初めまして、テックドクターのバックエンドエンジニアの魚木です。
私が担当するプロジェクトに、データベースのテーブルのあるカラムを前方一致検索する機能があります。そこに部分・後方一致検索もしたいという要望がありました。
そのデータベースはB+treeインデックスが使用されていますが、B+tree (または同系統のtree) インデックスは部分・後方一致検索は効率良くできないと言われています。
結果的に機能追加は見送られたのですが、前方・部分・後方一致検索の違いについて考えるよい機会になりました。
本記事は、B+treeが部分・後方一致検索を効率よくできない理由と、その代替手段として後方一致検索を高効率でする方法を説明します。
MySQLを前提としますが、インデックスの構造が同系統であれば同じような結論になります。
なぜ前方一致検索のみ高効率なのか
まずはtree構造が前方一致検索を効率よく処理できるしくみを説明します。ここではシンプルに、二分探索木で考えてみましょう。
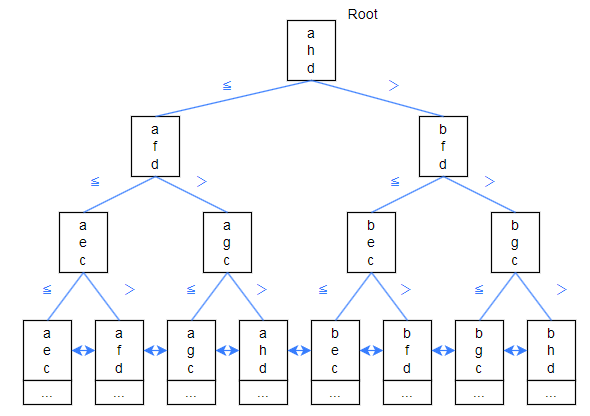
下記のような二分探索木があるとします。
- 葉ノードのみ実データを持ち、それ以外のノードはキーのみを持つ
- 隣接する葉ノードは相互にリンクされている
- キーは8個存在し、それぞれ "aec", "afd", "agc", "ahd", "bec", "bfd", "bgc", "bhd" のデータを持っており、辞書順でソート済みであるものとする。
図にすると、このようになります。
完全一致検索の場合
まず、完全一致検索について考えます。完全一致検索は前方一致検索の一種であるため、高効率に処理することができるはずです。
上記のtreeから、あるキーを持つ葉ノードを検索した場合……
- 根ノードの "ahd" と比較し、入力が "ahd" 以下であれば左のブランチを進みます。"ahd" より大きければ右のブランチを進みます。1つ階層を降りた時点で、入力と同じキーをもつ可能性のある葉ノードは8個から4個に絞られます。
- 同様の操作を深さ1のノードで行うと、候補がさらに4個から2個に絞られ、
- 同様の操作を深さ2のノードで行うと入力と同じキーを持つノードが特定されるか、存在しないことが判明します。

このように、treeの階層をひとつ降りるたびに候補が1/2ずつに絞られることが二分探索木の探索の効率の良さを生んでいます。
データベースでよく使われるB+treeは各ノードの保持するキーが複数になりますが、階層を降りる毎に候補が1/n (二分探索木の場合はnが2) に絞られるという点で同じです。
前方一致検索の場合
次に前方一致検索について考えます。
同じtreeで、"b" から始まるデータを全て取得したいとします。
下記の手順で、"b" から始まるキーを持つ葉ノードの中で、辞書順で一番早いものを1回の探索で特定することができます。
- 最初は根ノードで "ahd" と "b" を比較し、"b" の方が辞書順で遅いので右のブランチを進みます。
- 次は "bfd" と "b" の比較で "b" の方が辞書順で早いので左のブランチを進み、
- 同様に "bec" のノードでも左のブランチを進むことで左から5番目の葉ノードである "bec" が特定されます。

そこから図3の緑色の矢印のように、隣接ノードへのリンクを右方向に、"b" から始まらないキーを持つ葉ノードが出現するか (※)、終わりまで走査し終わるかのいずれかになるまで進みます。ここでは "bec"、"bfd"、"bgc"、"bhd" の4件が該当しました。
※葉ノードが辞書順でソート済みであるので、一度 "b" 以外から始まる葉ノードに到達したら、それ以降に "b" から始まる葉ノードは絶対に存在しません
今回は1文字の前方一致の例を示しましたが、前方一致検索の条件が2文字以上になっても基本的な考えは変わりません。肝心なことは、前方一致する辞書順で一番早いキーを持つ葉ノードを1回の探索で特定できることと、葉ノードの並びが辞書順でソート済みであるため効率的に処理できるということです。
後方一致検索の場合
最後に後方一致検索について考えてみます。
例えば "c" で終わるキーを持つ葉ノードを取得したいとしましょう。
上で説明したように、根ノードから左に降りることは条件に合致する候補を1~4番目に限定することです。また、右に降りることは5~8番目に限定することを意味します。
しかし、下の図4からわかるとおり、"c" で終わる葉ノードは左から1、3、5、7番目に存在し、どちらに降りたとしても条件に合致するキーが反対側にも存在することになってしまいます。
とりあえず、全てのノードで左に進んだとしましょう。偶然、一番左の葉ノードのキーが "aec" と "c" で終わっているので、前方一致検索と同様にそこから右のリンクを進んでみましょう。そうすると次の葉ノードのキーは "afd" であり "c" で終わりませんが、それで走査を打ち切れるでしょうか?
先に述べたように左から3、5、7番目にも "c" で終わるキーを持つ葉ノードが存在するので、走査を打ち切ってしまうと正しい結果は得られません。

別のデータセットであれば、偶然1番目にしか "c" で終わるキーを持つ葉ノードが存在しないこともあるかもしれませんが、いずれにせよ葉ノードを全て調べて結果的にわかることであって、tree構造自体が保証するものではありません。
これらのことから、後方一致検索は葉ノードを全走査しなければならず、大抵の場合とても非効率になります。部分一致検索も同じ理由で非効率になります。
(実際にはこの例のようにデータ数が少ない場合は全走査した方が効率が良い可能性が高いですが、データ数が増えたときのことを想像してみてください)
B+treeで高効率で (擬似的に) 後方一致検索をする方法
これまで述べたように、B+tree (または同系統のtree) で後方一致検索を効率よく行うことは原理的に不可能です。しかし、B+treeで後方一致検索と同じ結果を高効率で得る方法もあります。以下のような手順で実現することができます。
- 後方一致検索をしたいカラムを反転したカラムを追加する
- Generated Column (本記事はこれを使う)
- トリガー
- ...
- 反転したカラムのインデックスを作成する
- 後方一致検索対象の文字列を反転し、そのカラムを条件に前方一致検索する
後方一致検索をしたいカラムを反転したカラムを作成し、それに対してインデックスを作成することによって、後方一致検索を前方一致検索に変換することができます。上で説明したように前方一致検索は高効率で行えるので、事実上の後方一致検索を高速に行うことができます。
実際にやってみる
今回はGenerated Columnを使った方法で説明します。(後方一致検索をしたいカラムを反転したカラムさえあればいいので、トリガーでも実現可能です。)
Generated Columnの詳細は公式ドキュメントを参照していただきたいですが、ざっくりいうとカラム定義に式を使えるようにする機能です。
例えば、メールアドレスを保存するカラムが元からあるとして、それを参照しつつ反転したカラムを作成することができます。
このカラムは、参照元カラムの更新も反映されますし、インデックスを作ることもできます。
例として以下のような`email`カラムと`reverse_email`カラムを持ったusersテーブルを作成します。
CREATE TABLE users ( id INT AUTO_INCREMENT, email VARCHAR(255) UNIQUE, reverse_email VARCHAR(255) GENERATED ALWAYS AS (REVERSE(email)) VIRTUAL, PRIMARY KEY (id), index email_index(email), index reverse_emai_index(reverse_email) ); INSERT INTO users (email) VALUES ('test1@test.com'), ('test2@test.jp'), ('test3@test.com'), ('test4@test.jp'), ('test5@test.com'), ('test6@test.jp'), ('test7@test.com'), ('test8@test.jp') ; SELECT * FROM users; +----+----------------+----------------+ | id | email | reverse_email | +----+----------------+----------------+ | 1 | test1@test.com | moc.tset@1tset | | 2 | test2@test.jp | pj.tset@2tset | | 3 | test3@test.com | moc.tset@3tset | | 4 | test4@test.jp | pj.tset@4tset | | 5 | test5@test.com | moc.tset@5tset | | 6 | test6@test.jp | pj.tset@6tset | | 7 | test7@test.com | moc.tset@7tset | | 8 | test8@test.jp | pj.tset@8tset | +----+----------------+----------------+ 8 rows in set (0.00 sec)
emailとreverse_emailに対するインデックスを作成しており、SELECTの結果から想定通りにreverse_emailがemailを反転したものであることがわかります。
まずは、emailの「.com」後方一致検索をしてみます。
SELECT * FROM users WHERE email LIKE '%.com'; +----+----------------+----------------+ | id | email | reverse_email | +----+----------------+----------------+ | 1 | test1@test.com | moc.tset@1tset | | 3 | test3@test.com | moc.tset@3tset | | 5 | test5@test.com | moc.tset@5tset | | 7 | test7@test.com | moc.tset@7tset | +----+----------------+----------------+ 4 rows in set (0.09 sec) EXPLAIN SELECT * FROM users WHERE email LIKE '%.com'\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: users partitions: NULL type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 8 filtered: 12.50 Extra: Using where 1 row in set, 1 warning (0.01 sec)
取得結果は正しいですが、EXPLAINのtypeをみるとALLとなっており、全表走査していることが分かります。
次に、後方一致検索用の文字列を反転し前方一致検索用の文字列にして、reverse_emailに対して検索します。
SELECT * FROM users WHERE reverse_email LIKE REVERSE('%.com'); +----+----------------+----------------+ | id | email | reverse_email | +----+----------------+----------------+ | 1 | test1@test.com | moc.tset@1tset | | 3 | test3@test.com | moc.tset@3tset | | 5 | test5@test.com | moc.tset@5tset | | 7 | test7@test.com | moc.tset@7tset | +----+----------------+----------------+ 4 rows in set (0.13 sec) EXPLAIN SELECT * FROM users WHERE reverse_email LIKE REVERSE('%.com')\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: users partitions: NULL type: range possible_keys: reverse_emai_index key: reverse_emai_index key_len: 1023 ref: NULL rows: 4 filtered: 100.00 Extra: Using where 1 row in set, 1 warning (0.07 sec)
emailに対する後方一致検索と同じ結果が得られました。また、EXPLAINのtypeがrange、keyがreverse_email_indexとなっていて、インデックスを使っていることがわかります。
このように、Generated Columnを使えば後方一致検索を高効率で行うことができます。
(例ではデータ数が小さいので、emailに対する後方一致検索の方が早いですが、データ数が大きくなるとreverse_emailに対する前方一致検索の方が早くなります)
注意点
この方法で事実上の後方一致検索を高効率でできますが、別のコストが増加する場合もあるので注意が必要です。
- インデックスの追加による更新系クエリの性能の悪化
- アプリケーションで後方一致検索の要求をうまく処理する必要がある
実装にあたってはこれらのコストを考慮して、本当に後方一致検索が必要かどうかを判断する必要があります。
ちなみに部分一致検索はこの方法ではできませんし、私の知る限りB+tree (または同系統のtree) で高効率で部分一致検索をする方法はありません。
この記事を読んで、少しでもテックドクターに興味を持っていただけたら嬉しく思います。
今後も技術系の記事を書いていく予定なので、よろしくお願いします。

書いた人:魚木